Summary
I train a toy language model to perform two-digit subtraction. I find that the model exhibits grokking (memorization -> generalization) during training, and find that some of the signal in the activations is periodic (like in Neel Nanda’s modular addition paper).
Intro
I’m trying to skill up into AI / Transformer Language Models / Mechanistic Interpretability research. I’m a huge fan of Neel Nanda (and co-authors’) paper on modular addition, so I want to study a language model trained on a task that I bet will learn something similar to what was found in that paper (namely, a trig identity). I’m going to train a simple transformer to perform two-digit subtraction.
Model Details
I’m going to be using the TransformerLens package to set up and analyze the transformer. I’ll train a transformer to perform two-digit subtraction. The input to the model is of the form “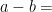
![a,b\in [0,99]](https://s0.wp.com/latex.php?latex=a%2Cb%5Cin+%5B0%2C99%5D&bg=ffffff&fg=000&s=0&c=20201002)


I’ll study a one-layer transformer with 


There are only 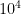





Training Dynamics
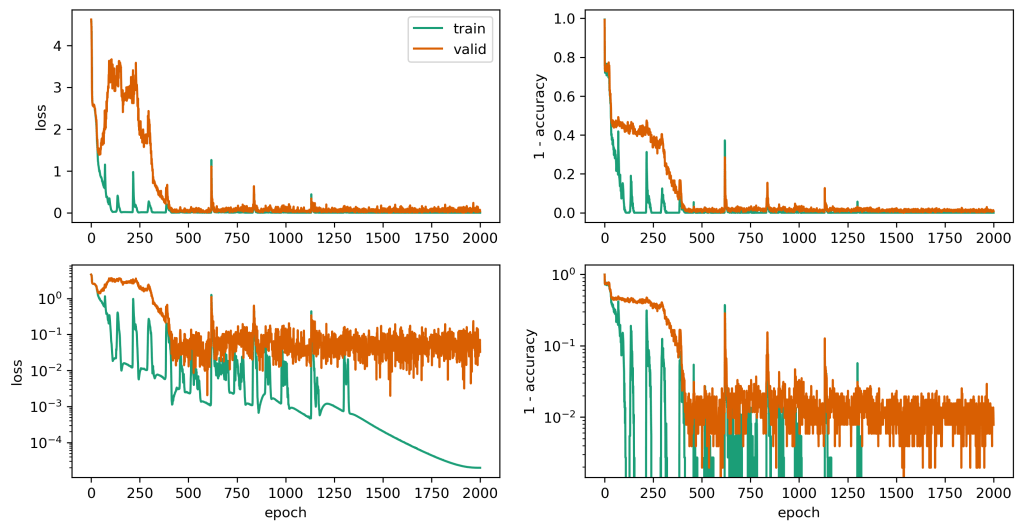
This model exhibits grokking. We see that the loss and accuracy of the train data quickly become small while the validation loss and accuracy remain high (see below). After a few hundred epochs, the validation loss becomes small. Surprisingly, there are a number of ‘spikes’ in the loss curve. I don’t know what’s happening in the model, but I bet it’s finding a bunch of valid solutions and jumping between them (or maybe my learning rate was too high, or maybe I just got unlucky with my batches, or maybe there was too much momentum from AdamW). As I’ll show, the model uses key frequencies to perform its calculation, and these peaks probably represent changes in the dominant frequencies it uses. Note here that I’m calculating the training loss using the full training set (30% of the problem space), whereas I’m only sampling one batch of size 256 to calculate the validation loss / accuracy each epoch.
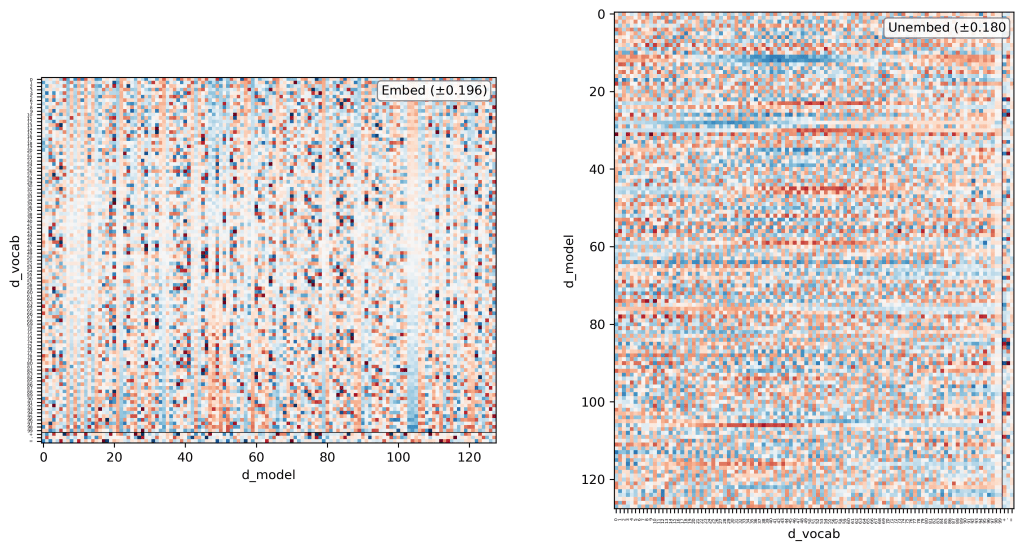
Matrix Periodicity
Each dimension of the model exhibits clear periodicity in both the embedding and unembedding matrices. Specifically, this periodicity appears in the d_vocab direction in each dimension of the model. Below is a figure of the embedding and unembedding matrices, where the color shows the weight magnitude, and the colorbar is symmetric around the labeled value in the text box:
If we take a Fourier Transform in the d_vocab direction for each of these matrices, then form the power spectrum, then take the mean power over the model dimension direction, we get the following spectra:
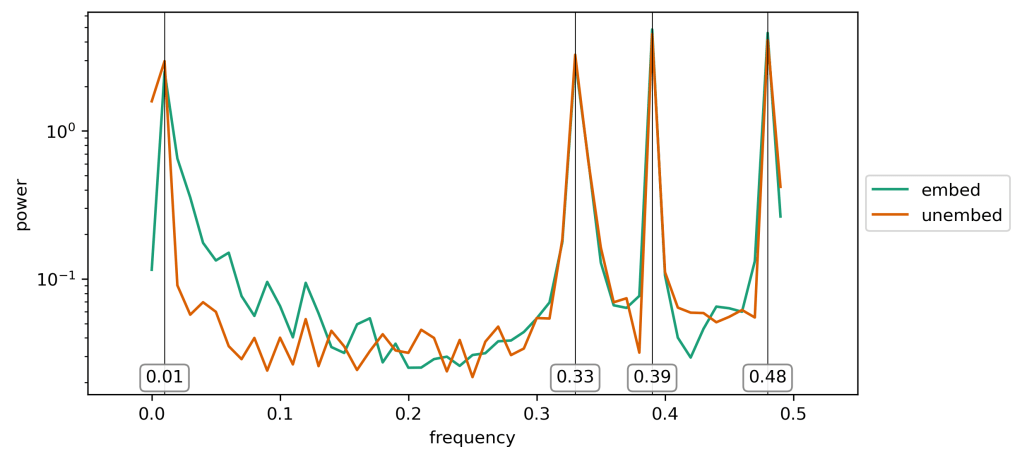
So it looks like the model basically turns our tokens into, primarily, four dominant frequencies which are noted above. Very cool. Although, as we’ll see below, the peak at 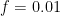
What do the residual stream activations look like?
Fortunately this problem lives in a small universe. There are 100 possible values of
I’m being largely inspired by Chapter 1, part 5 ARENA notebook in my thinking of this problem, and wanted to shout that out before I move ahead. In that notebook, Fourier Transforms are taken with custom functions, but I’m going to be using the NumPy FFT module in this analysis. The FFT module projects onto a basis of complex exponentials (e.g., a series in time 

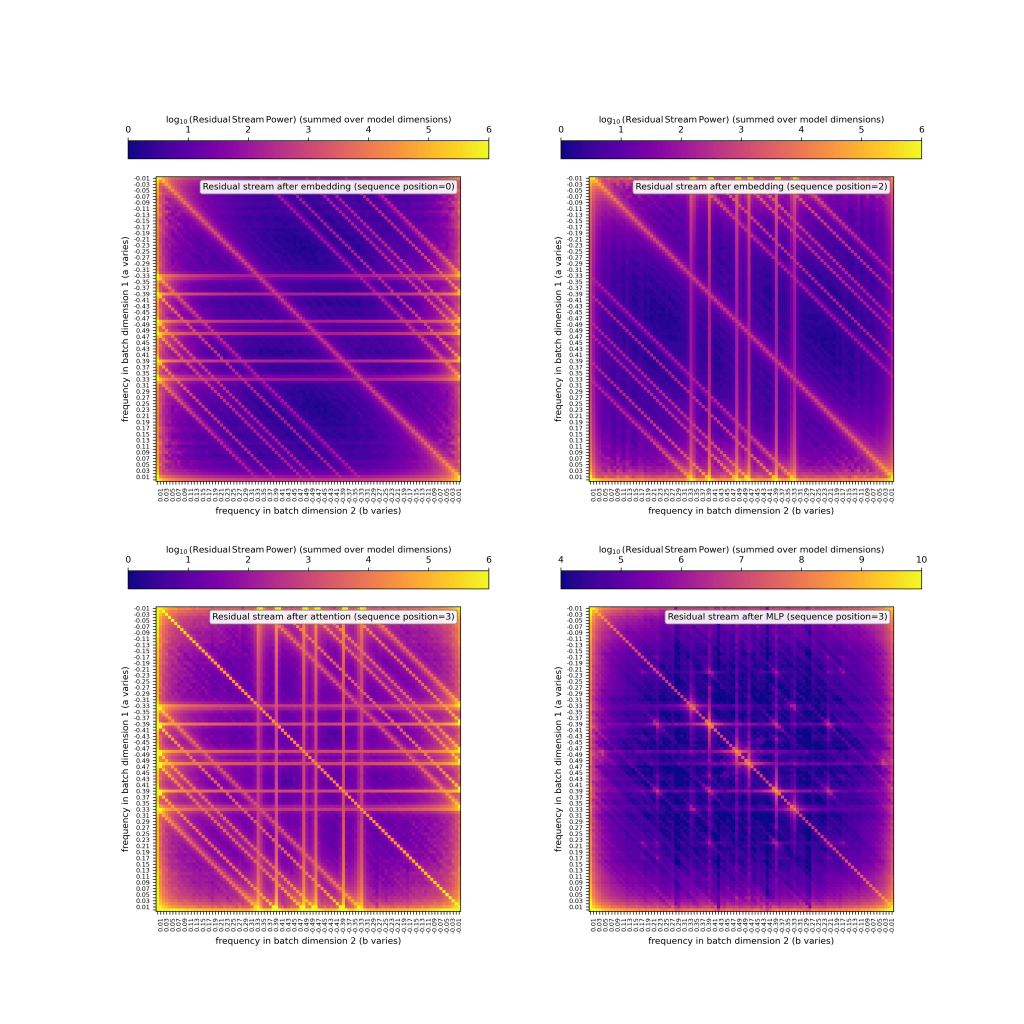
Below I plot the 2D transformed activations of four different spots within the model’s context. In the upper row, I plot (left) the embeddings in the residual stream at sequence position 0 (
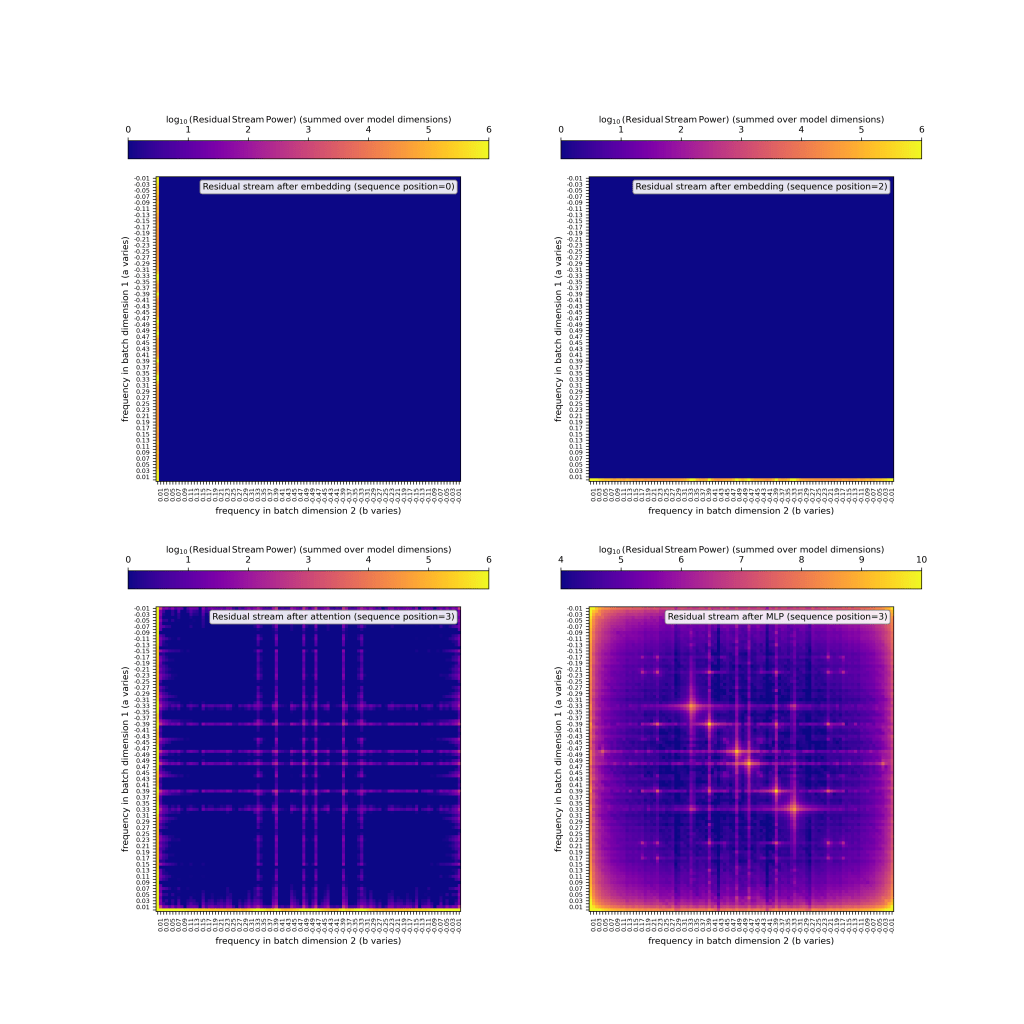
There’s a few features to note:
- The activations of token
- Similarly, the activations of token
- Attention largely seems to be copying the power from each of those positions into position 3. I haven’t verified that it’s doing this, but it’s moving power into the same spots in frequency space, so it’s at least copying-adjacent. (Although, from looking at this in more detail later, it’s certainly doing something more complicated than copying! It would be fun to figure this out.)
- The MLP is spraying power from low frequencies to higher frequencies, and is making things much less sparse!
The last of these things is upsetting and complicated, so I’ll look into that a bit below, but first I want to quickly note that above I’m showing the power spectra for all
My interpretation here is largely the same — it’s just interesting to me that including all of the positive and negative problems in my batch manages to cancel out these extra features in the power spectra. I would naively think “both have equal and opposite power at the same frequencies, so they should add their power together and reinforce the features you see!” But — that’s not what’s happening. Maybe I’m just unfamiliar with how 2D FTs work, or maybe I’m thinking about this wrong. Interested in feedback / thoughts here.
In what way are the activations not sparse in frequency space?
So we see above that the activations are not as sparse as hoped in frequency space. This can be seen in a couple of ways, namely: power occupies many frequencies in the first row / column of e.g., the embeddings and post-attention, and also power occupies…a lot of the plot after the MLP acts.
It turns out that power is enveloped by a really simple 



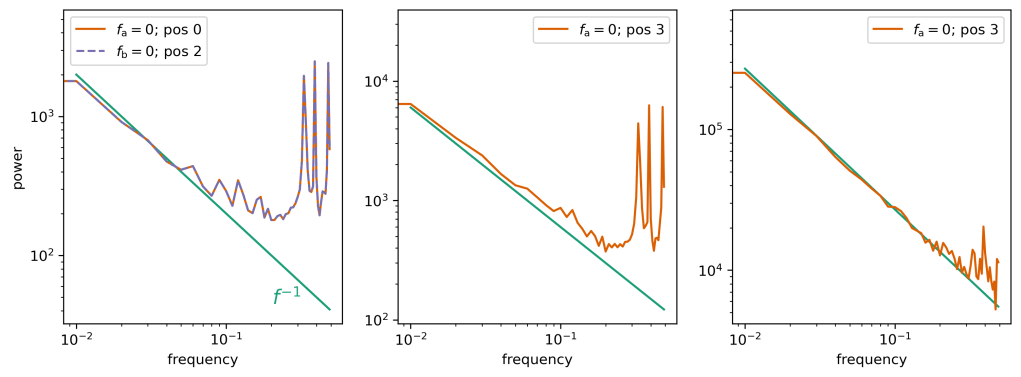
One of the reasons that I think that the “key frequencies” aren’t used in predicting the 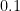
Wrap up & Code Availability
So my choice to split the +/- out from the last value
The code I used to train the model can be found in this colab notebook, and the code I used to create the plots can be found in this Github repo, which I’ll update as I continue along this project!
Acknowledgments
Big thanks to Adam Jermyn for helping me find my footing into AI safety work and for providing me with mentorship and guidance, and also for providing feedback on an early version of this blog. Thanks also to Neel Nanda for recommending that I keep a record of small projects (like this one!) in blog form as I skill up.

Leave a comment